Model
Here we are, the definition of our network’s model!
First model
Almost all the function we need is already existant inside the Pytorch library, but it’s a very low level (compared to some other) library, so we will add a little method for getting a simple ReLU layer.
def linear_relu(dim_in, dim_out):
"""
Create a linear reLU layer.
"""
return [nn.Linear(dim_in, dim_out), nn.ReLU(inplace=True)]
A good practice is to write all our custom model and related methods to the same file, as models/cutom_models.py for example. In the first time, we will only
create a two hidden layers fully connected network, with 256 neurons per layer.
class FullyConnected(nn.Module):
"""
Simple fully connected classification model.
"""
def __init__(self, input_size, num_classes):
super(FullyConnected, self).__init__()
self.classifier = nn.Sequential(
*linear_relu(input_size, 256), # First hidden layer
*linear_relu(256, 256), # Second one
nn.Linear(256, num_classes)
)
def forward(self, x):
x = x.view(x.size()[0], -1)
y = self.classifier(x)
return y
The forward(x) method define the operation applied to our tensors when we made a inference with our model.
Note
As usual, the class bodies are already generated with the JAW project.
Regularization
Let’s see another more avanced example. We will regularize our previous model.
A regularization is a constraint imposed on the model during its training aimed at limiting overfitting. Another way of defining it is to say that we are trying to prefer a model simple to a complex, therefore maximizing the capacity for generalization. We can find here a more mathematical definition.
Here we will use the L2 regularization. This technique aims to reduce the weights of the learned model proportionally to the sum of the squares of these same weights, according to the following formula:
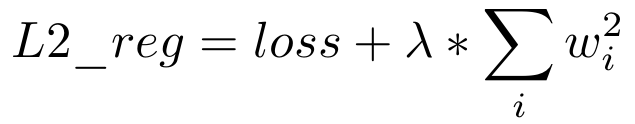
Some fiew changes are necessary. We can’t save our model as one, we declare each layer as one and reconstruct the model inside the forward method. We also add
a penality method for apply the formula and a l2_reg parameter, which is our lambda factor.
class FullyConnectedRegularized(nn.Module):
def __init__(self, input_size, num_classes, l2_reg):
super(FullyConnectedRegularized, self).__init__()
self.l2_reg = l2_reg
self.lin1 = nn.Linear(input_size, 256)
self.lin2 = nn.Linear(256, 256)
self.lin3 = nn.Linear(256, num_classes)
def penalty(self):
return self.l2_reg * (
self.lin1.weight.norm(2)
+ self.lin2.weight.norm(2)
+ self.lin3.weight.norm(2)
)
def forward(self, x):
x = x.view(x.size()[0], -1)
# Reconstruction of our model
x = nn.functional.relu(self.lin1(x))
x = nn.functional.relu(self.lin2(x))
y = self.lin3(x)
return y
We also have to update our train function for calling this penality method when required.
def train(model, loader, f_loss, optimizer, device):
model.train()
for (inputs, targets) in enumerate(loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = f_loss(outputs, targets)
optimizer.zero_grad()
loss.backward()
# whatever the model used, we check if it contain a "penality" method
if hasattr(model, "penalty"):
model.penalty().backward()
optimizer.step()
Warning
We call the lamda factor of the formula l2_reg inside this example class. Despite of the fact that lambda term is reserved in Python language, keep in mind
for your project that isn’t a very good name.